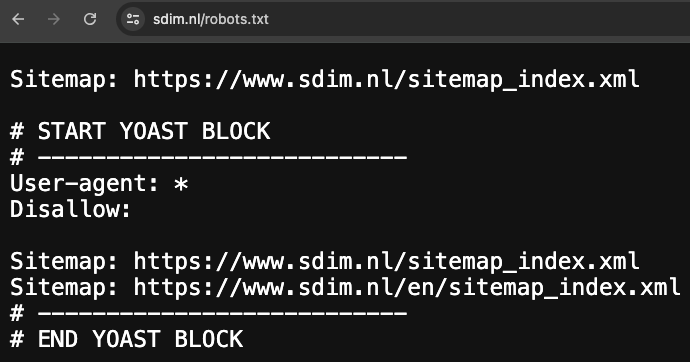
De Robots.txt is een publiekelijk toegankelijk tekstbestandje dat in de root van de webserver te vinden is. Het is een belangrijk bestandje omdat het vertelt welke gedeeltes van een website een zoekmachine crawler, zoals Googlebot voor Google, niet mag bezoeken. De regels die ingesteld worden kunnen de prestaties van de website flink beïnvloeden. Als een website geen robots.txt geplaatst heeft, zal een bot mogelijk de gehele website crawlen.
Als de crawler van een zoekmachine de website bezoekt, checkt het eerst voor het bestaan van een Robots.txt bestand in de root van het domein. Dit tekst bestandje is onderdeel van de Robots Exclusion Protocol (REP). Dit protocol is opgericht als regulatie over hoe robots het web mogen crawlen en indexeren. Zo kun je middels de robots.txt uitsluiten dat een zoekmachine bepaalde subfolders van het CMS kan crawlen en indexeren. Het is goed om te beseffen dat de richtlijnen in de robots.txt strenge signalen zijn en geen verplichtingen voor een zoekmachine. Een zoekmachine kan er dus voor kiezen om gedeeltes van de robots.txt te negeren.
Robots.txt en SEO
Vanwege de directe link met de crawlers van zoekmachines is de robots.txt een belangrijk bestand voor SEO specialisten. Voor SEO is het van belang dat de belangrijke pagina’s van een website toegankelijk zijn en geïndexeerd kunnen worden. Daarnaast wordt gezorgd dat juist aan de niet-belangrijke pagina’s geen aandacht besteed wordt door een crawler. De robots.txt kan hier cruciaal in zijn. Één enkele regel in de robots.txt kan ervoor zorgen dat een groot gedeelte van de website niet geïndexeerd gaat worden.
In de robots.txt wordt aangegeven hoe zoekmachines om moeten gaan met de website. Dit kan verder gespecificeerd worden per zoekmachine crawler, ook wel User Agent genoemd. Per User-Agent kun je aparte regels instellen. De meest bekende User Agents zijn:
Googlebot (Google)
Googlebot-Image (Google images)
Bingbot (Microsoft Bing)
Slurp (Yahoo)
Baiduspider (Baidu)
DuckDuckBot (Duckduckgo)
Applebot (Apple)
* (alle User-Agents)
Hierboven zijn slechts de bekendste user-agents, maar zo zijn er nog duizenden anderen die websites crawlen.
Voorbeeld robots.txt
Een robots.txt wordt opgebouwd door per User-Agent aan te geven welke richtlijnen er gelden. Dit kan gedaan worden door alle User-Agents aan te spreken middels een *, of de User-Agent specifiek te benoemen. Voor de robots.txt geldt voor Googlebot en Bingbot dat een specifiekere regel leidend is. Een voorbeeld van een robots.txt is als volgt (voor WordPress):
In het bovenstaande voorbeeld wordt bepaald dat voor alle User-Agents (User-agent: *) geldt dat zij niets in de folder wp-admin (Disallow: /wp-admin/) mogen crawlen en indexeren. De specifiekere regel daaronder (Allow: /wp-admin/admin-ajax.php) werkt in dit geval als een soort filter. Hierdoor komen crawlers wel bij het bestand admin-ajax.php.
Wil je dat bepaalde bestanden of afbeeldingen overgeslagen moeten worden? Dan geef je dit aan in een specifieke regel:
User-agent: *
Disallow: /prive/
Bron: keycdn.com
Veelgemaakte fouten met robots.txt
Een robots.txt geeft dus richtlijnen aan een crawler. Helaas komen fouten in deze bestanden vaak voor, wat grote gevolgen kan hebben voor de website en het verkeer. Hieronder een aantal van de meest voorkomende fouten in de robots.txt.
Privé bestanden worden toch geïndexeerd door bepaalde zoekmachines. Een robots.txt bevat richtlijnen die genegeerd kunnen worden door een bot, met name door de wat minder gerespecteerde bots. Het is dus geen garantie dat een folder niet bezocht zal gaan worden door een bot. Wil je bestanden of folder echt afschermen zijn andere methodes zoals een inlog met wachtwoord beter.
Er is een disallow regel ingesteld, maar mijn bestand/pagina staat toch in de zoekresultaten. Dat een bestand of folder uitgesloten wordt via een robots.txt betekent niet dat een crawler deze nooit zal vinden en indexeren. Er kan namelijk via andere websites naar deze bestanden en folder gelinkt worden. Daarom wordt gebruik van de noindex meta directive aangeraden om pagina’s uit te sluiten van indexatie.
De hele website wordt uitgesloten door ‘Disallow: /’ in te voeren. Hierdoor mag geen enkele folder of bestand achter de root gecrawld en geïndexeerd mag worden. Zorg dat er geen delen van de website uitgesloten worden die je wilt tonen in de zoekresultaten.
Er wordt gebruik gemaakt van absolute URLs of URLs van andere domeinen. Een robots.txt geldt alleen voor het domein waarop het geplaatst is en accepteer alleen relatieve URLs voor subfolders of bestanden (behalve voor de sitemap). Het is niet mogelijk om met absolute URLs te verwijzen naar een andere site.
De robots.txt staat in een subfolder van het domein. De robots.txt hoort in de root van het domein te staan.
Een verwijzing naar een URL met trailing slash als deze er geen heeft.
Een Disallow regel starten zonder slash.
Een URL met een hoofdletter schrijven als deze er geen heeft (of andersom).
De sitemap verwijzing via een relatieve URL plaatsen. De verwijzing naar een sitemap moet via een absolute URL zijn.
Robots.txt: Best practices
Voor de robots.txt zijn er standaard regels waar het aan moet voldoen. Toch zijn er een aantal best practices wanneer je een robots.txt maakt:
Sluit bepaalde malware bots uit via een aparte regel:
User-agent: NaamVanBot
Disallow: /
De robots.txt is publiekelijk toegankelijk dus noteer geen namen van privé mappen.
Het is aan te raden een verwijzing naar de sitemap te plaatsen in de robots.txt. Zo is een crawler altijd op de hoogte van de locatie van de sitemap.
Sitemap: http://www.example.com/sitemap.xml
De volgorde van de regels maakt uit. Standaard geldt dat de eerste regel altijd leidend is. Voor Googlebot en Bingbot geldt dat specifieke regels winnen.
Robots.txt maken
Het maken van een robots.txt klinkt ingewikkeld, maar gelukkig is het vrij eenvoudig. Er zijn een aantal manieren om een robots.txt te maken.
Generator
Het is mogelijk om via zogeheten Robots.txt generators robots.txt bestanden aan te maken en te downloaden. Voorbeelden van dergelijke generators zijn:
De populaire WordPress plugins Yoast en Rank Math maken het eenvoudig om een robots.txt te creëren voor WordPress websites. Vanuit de tool kun je een robots.txt aanmaken en eventueel aanpassen.
Handmatig
Natuurlijk kun je een robots.txt ook handmatig aanmaken. Hierdoor maak je een nieuw bestand op je PC met behulp van een programma als Notepad. Hierin verwerk je de gewenste regels en slaat deze op als robots.txt. Zorg dat je het bestand opslaat in een .txt format. Tenslotte plaats je dit bestand via een FTP client in de root van je website.
Robots.txt tester
Als je handmatig of via een generator een robots.txt maakt is het verstandig deze te valideren via een robots.txt tester. Hier heeft Google een eigen robots.txt testing tool voor beschikbaar gesteld. Deze werkt alleen voor proporties die gevalideerd zijn door Google. Buiten Google zijn er ook tools beschikbaar om de robots.txt te testen. Denk bijvoorbeeld aan de online tool van TechnicalSEO.
Tom Duivenvoorden versterkte het SDIM team in juli 2020. Hij heeft een Master Marketing Management en werkte enkele jaren als all-round marketeer in de kaasbranche. Daarna stapte hij over naar digital marketing. Tom is een van onze experts in complexe technische vraagstukken.