Google MUVERA is een geavanceerd zoekalgoritme dat de zoekresultaten verbetert door beter te begrijpen wat gebruikers zoeken, niet alleen welke woorden ze gebruiken. Het maakt gebruik van multi-vector retrieval en fixed-dimensional encodings om zoekopdrachten sneller en relevanter te verwerken. In dit artikel leggen we uit wat MUVERA is en hoe het de SEO-strategieën kan beïnvloeden.
Ga snel naar
Wat is Google MUVERA?
MUVERA, oftewel Multi-Vector Retrieval via Fixed Dimensional Encodings, is een geavanceerd zoekalgoritme van Google. Het maakt zoekresultaten slimmer door beter te begrijpen wat mensen echt zoeken, in plaats van alleen te kijken naar de woorden die ze gebruiken. Dit betekent dat Google nu de juiste informatie veel sneller kan vinden, zelfs als de zoekopdracht niet precies overeenkomt met de woorden op een pagina. In tegenstelling tot oudere modellen als PLAID, heeft het betere precisie met snellere verwerkingstijden.
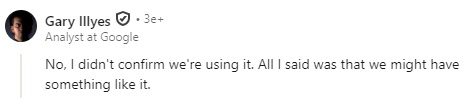
Google pretendeert al langere tijd dat het zoektermen kan begrijpen en context kan lezen. Ik was dan ook in de veronderstelling dat Google dit al die tijd al deed, maar blijkbaar is MUVERA een vernieuwing of toevoeging. Ook toen de community vroeg of MUVERA nu dan gebruikt wordt in de zoekresultaten kwam spokesperson Gary Illyes met een antwoord.
Hierin wordt dus niet bevestigd dat Google echt gebruik maakt van MUVERA, of nouja, hij bevestigt dat hij dat niet zelf heeft gezegd. Het gebruikelijke, cryptische antwoord waar we het eigenlijk altijd al mee moeten doen. Het interessante stuk zit in het laatste deel van de reactie. Voor de zoekresultaten wordt “mogelijk” iets vergelijkbaars gebruikt. Of dit systeem al even goed werkte als MUVERA, of dat MUVERA een upgrade voor het bestaande systeem is, is nog even gissen. Het zegt in ieder geval wel iets over de manier hoe zoektermen omgezet worden naar intenties en daarmee passende resultaten.
Maar wat is een vector überhaupt?
Om een beter beeld te krijgen van de werking van MUVERA is het belangrijk om te weten wat een vector is. Een vector, in de context van zoektermen, is als een digitale vingerafdruk van een woord of idee. Een computer werkt feitelijk enkel met een 1 of een 0 en niet met woorden. Zo is het woord SDIM feitelijk “01010011 01000100 01001001 01001101” in binary taal. Een vector is dus een soort wiskundige manier om de betekenis van een woord om te zetten in getallen, zodat de computer het kan begrijpen en vergelijken.
Dit klinkt nog steeds technisch, dus laat ik het proberen uit te leggen: stel je voor dat je het woord “apple” hebt. Om dit te begrijpen, wordt het woord omgezet in een vector, een lijst van getallen. Elk getal in die lijst vertegenwoordigt een bepaald aspect van de betekenis van het woord. Bijvoorbeeld:
1 getal kan verwijzen naar de categorie fruit.
Een ander getal kan aangeven dat het een object is dat je kunt eten.
Nog een ander getal kan aangeven dat een appel vaak een ronde vorm heeft.
Maar ook kan een getal verwijzen naar het merk en bedrijf Apple.
Deze getallen samen vormen de vector voor het woord “apple”.
Een zoekmachine gebruikt deze vectoren om dus duidelijk een context te bepalen en de samenhang tussen de woorden, oftewel semantiek. Als iemand zoekt naar “hoe snijd ik een appel?”, is de zoekmachine niet alleen op zoek naar de exacte woorden “hoe”, “snijd”, “appel”, maar ook naar de vectoren van die woorden. Zo kan het begrijpen dat de vraag eigenlijk draait om het snijden van een fruit en kan het relevante artikelen of video’s tonen, zelfs als ze niet de woorden “snijd een appel” exact gebruiken, maar wel gerelateerde termen zoals “fruit snijden” of “gezonde recepten”. Het begrijpt door de vectoren rondom snijden ook direct dat je het fruit bedoelt en niet bezig bent met het in stukjes hakken van je smartphone.
Vervolgens gebruikt Google deze vectoren om een vergelijking te maken met de vectoren die ze hebben gemaakt met de webpagina’s in de index. Zo kan het bepalen wat het meest semantisch relevant is voor jouw zoekterm.
Hoe werkt MUVERA en waarom is het speciaal?
Disclaimer: de volgende uitleg is een vermoeden, want door de blackbox van Google weet je het nooit zeker.
Google gebruikt dus al langere tijd vectoren in hun zoekalgoritmes, dat wisten we al. “Semantic search” bestaat namelijk al een stuk langer. Nu is dit vooral via word embeddings (zoals Word2Vec en later BERT) om de semantische betekenis van zoektermen te begrijpen. Dus wat maakt Multi-Vector Retrieval (en MUVERA) nu anders?
De crux zit hem niet zozeer in “Multi-Vector”. We vermoeden dat Google dit al langere tijd deed. Immers, hoe vaak kreeg jij een YouTube video te zien waarbij iemand de nieuwe Iphone ontleed als beste zoekresultaat voor “cut apple”. Het verschil met MUVERA is dat het deze multi-vector data nu omvormt naar fixed-dimensional vectors (FDE’s), wat het zoeken sneller en schaalbaarder maakt.
Hoe werkt Fixed Dimensional Encoding (FDE)? In plaats van deze vectoren apart te houden en één voor één te verwerken, wordt Fixed Dimensional Encoding (FDE) gebruikt om deze vectoren te combineren in één enkele vector. Het woord “fixed” betekent dat de dimensie van deze gecombineerde vector altijd hetzelfde is, ongeacht het aantal vectoren dat wordt gecombineerd. Stel je voor dat je een verzameling puzzelstukken hebt. Elk puzzelstuk is een vector die een deel van de betekenis bevat. FDE is het proces waarbij al deze puzzelstukjes in één stevige afgewerkte puzzel worden gezet. Het maakt het makkelijker voor Google om de volledige afbeelding (de betekenis) snel te begrijpen. Simpel gezegd: Google weet altijd hoeveel getallen er in een vector zitten (bijvoorbeeld 128 getallen, 512 getallen, etc.), waardoor de berekeningen snel en voorspelbaar blijven.
Wat betekent dit voor SEO?
Om kort te zijn: feitelijk verandert er niets. Maar voordat je stopt met lezen, laat het me uitleggen.
Er is geen nieuw wapen in het arsenaal van een SEO specialist gekomen. De zoekresultaten werken nog altijd hetzelfde (met vectoren) waardoor je pagina semantisch op te bouwen is. Je hoeft dus nog steeds niet jouw zoektermen te spammen over een pagina heen. Met MUVERA zijn er echter een aantal dingen wat je moet begrijpen:
Snellere verwerking van zoekopdrachten: Het is niet alleen nauwkeuriger, maar MUVERA is ook snel. Het gebruikt slimme technieken om meerdere vectoren tegelijk te verwerken, waardoor zoekresultaten veel sneller zijn. En ook bij de indexatie betekent dit dat betekent Google snel kan begrijpen waar een pagina over gaat, zelfs als die veel verschillende onderwerpen behandelt.
Verhoogde relevantie: Omdat MUVERA Google helpt om verschillende aspecten van een pagina beter te begrijpen, kunnen de zoekresultaten relevanter worden voor de zoekopdracht van een gebruiker. Dit betekent dat als je zoekt naar iets specifieks, zoals “hoe je gezond kunt koken”, Google ook pagina’s kan vinden die gerelateerde onderwerpen bevatten, zoals gezonde recepten of maaltijdplannen, zelfs als die woorden niet letterlijk in de zoekopdracht staan.
Dus als ik iets wil meegeven na dit technische verhaal voor wat voor jouw website relevant is:
Focus op semantiek en gebruikersintentie. Zorg ervoor dat je content niet alleen zoekwoorden bevat, maar ook de betekenis en context van die zoekwoorden goed weergeeft. Gebruik synoniemen en verwante termen. Bijvoorbeeld, als je schrijft over “gezonde voeding”, denk dan aan woorden zoals “gezonde recepten”, “dieet”, “voedingsstoffen”. Dit zorgt ervoor dat je pagina goed scoort voor een bredere reeks zoekopdrachten die aan dezelfde zoekintentie voldoen.
Creëer contentclusters die verschillende gerelateerde onderwerpen behandelen en logisch gestructureerd zijn. Maak gedetailleerde pagina’s die verschillende subonderwerpen behandelen die samen een groter thema vormen (bijvoorbeeld een hoofdartikel over “gezonde voeding” met afzonderlijke secties over groenten, fruit, diëten, etc.).
Wat denken wij van deze ontwikkeling?
Dat er qua werkzaamheden en zoekresultaten in principe niets verandert, wil niet zeggen dat het niet een ontwikkeling is dat verder gaat dan de zoekresultaten. Ons vermoeden is dat dit een efficiëntie en voorbereidingsslag is dat te maken heeft met AI search binnen Google’s zoekresultaten. De verwachting (of hoop) van Google is dat men in de toekomst met veel uitgebreidere zoektermen (prompts) gaat werken en dus feitelijk elk zoekterm uniek gaat worden. Dat brengt dat een flinke dosis complexiteit met zich mee, omdat er dan nóg meer vectoren relevant zijn voor de gebruiker. Het werken aan een algoritme dat sneller en efficiënter om kan gaan met het multi-vector concept is dan ook een no-brainer. AI Search is hier om te blijven.
Tom Duivenvoorden versterkte het SDIM team in juli 2020. Hij heeft een Master Marketing Management en werkte enkele jaren als all-round marketeer in de kaasbranche. Daarna stapte hij over naar digital marketing. Tom is een van onze experts in complexe technische vraagstukken.