Een zoekmachine gebruiken we allemaal, vaak meerdere keren per dag. Maar hoe werkt een zoekmachine eigenlijk?
Wat is crawlen?
Crawlen is het proces van het doorzoeken van een website door een spider, bot of robot, meestal door een zoekmachine. Zoekmachines maken gebruik van crawlen om zoveel mogelijk URL’s te vinden.
Het crawlproces begint met een lijst van bekende URL’s die tijdens eerdere crawls gevonden zijn en sitemaps die door website eigenaren via Google Search Console zijn verstrekt. Webcrawlers gebruiken links op deze websites om andere pagina’s te ontdekken. Ze gaan van link naar link en sturen informatie over de gevonden webpagina’s terug naar de Google-servers.
Zo signaleren de crawlers niet alleen welke nieuwe sites er gevonden worden, maar ook of er wijzigingen in bestaande sites hebben plaatsgevonden en welke links niet meer bestaan of toegankelijk zijn. Als een pagina bereikbaar is voor een zoekmachine, dan is deze ‘crawlbaar’.
Crawlbudget
Crawlers hebben voor elke website een crawlbudget. Het crawlbudget voor je website is de hoeveelheid pagina’s dat een zoekmachine op de website crawled, voordat de crawler de website verlaat. De hoeveelheid pagina’s dat een zoekmachine crawled is afhankelijk van de grootte van de website, de snelheid van de website en het aantal externe links die naar de website leiden.
Het is belangrijk dat de crawler het crawlbudget zo efficiënt mogelijk kan gebruiken. Als de website bijvoorbeeld veel duplicate content of redirects bevat heeft dit een negatieve invloed op het aantal relevante URL’s dat de crawler kan bereiken.
Wat is indexeren?
Indexeren betekent het verzamelen van informatie die op webpagina’s aanwezig is, met als doel relevante zoekresultaten weer te geven in zoekmachines. Pagina’s die geïndexeerd mogen worden noemen we indexeerbaar.
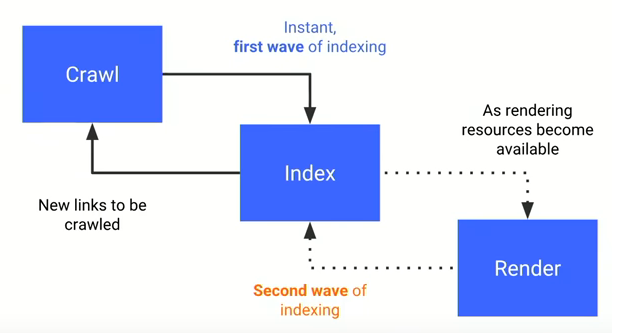
Wanneer crawlers zo’n indexeerbare website tegenkomen wordt de URL doorgegeven aan de Google Index. De Index analyseert de content op de webpagina en probeert zo om de content op de webpagina te begrijpen. Developers kunnen de Index helpen om de content op de pagina te begrijpen door het toevoegen van structured data.
Renderen
Wanneer een website voornamelijk uit platte HTML code bestaat die door de server wordt geleverd kan deze razendsnel worden opgepakt door een bot. Echter, steeds vaker bevatten websites JavaScript code. Crawlers hebben de grootste moeite om te begrijpen wat er op deze websites staat. De robot ontvangt namelijk een haast leeg HTML document met JavaScript. Om de JavaScript te verwerken gebruikt Googlebot een eigen web rendering service (WRS) voor het renderen van JavaScript. In het rendering proces wordt alle JavaScript code op de website uitgevoerd, zodat de Index ziet welke content er op de pagina staat. Nieuwe URL’s die tijdens het rendering proces van JavaScript zijn gevonden worden aan de Crawler teruggegeven.
Bron: Google IO 2018
Het uitvoeren van JavaScript kost veel tijd voor een bot. Wanneer de website veel JavaScript bevat moet Googlebot het rendering proces herhalen om content en nieuwe links te bereiken. Deze vertraging kan ervoor zorgen dat niet alle pagina’s op de website geïndexeerd worden. Een oplossing hiervoor kan gevonden worden in de implementatie van server-side rendering.
Alle relevante informatie wordt vervolgens geordend in de Index. Volgens Google bevat de Google Zoeken-index honderden miljarden webpagina’s en is deze meer dan 100.000.000 GB groot.
Wat gebeurt er als iemand een zoekopdracht in Google invoert?
Wanneer er een zoekopdracht in Google geplaatst wordt doorzoekt Google de Index, op zoek naar pagina’s waarin de zoekterm voorkomt die ingevoerd is in Google. Vaak zijn er honderdduizenden mogelijke resultaten.
Hoe bepaalt Google welke zoekresultaten getoond worden en op welke positie?
Aan de hand van ranking factoren bepaalt Google in welke volgorde de zoekresultaten worden weergegeven. Het algoritme van Google beoordeelt websites op honderden verschillende factoren.
De websites worden beoordeeld op:
Content
Techniek
Autoriteit
Autoriteit: Het belang van een website wordt bepaald door te kijken naar de hoeveelheid links die naar de betreffende website verwijzen, hoe belangrijk deze links zijn en vanaf welk domein de links afkomstig zijn.
Content: Het belang van een website wordt bepaald door het kijken naar de kwaliteit van de content en of de content aansluit bij de zoekintentie van de gebruiker. Het is belangrijk om bezoekers van uw website te voorzien van hoge kwaliteit content.
Techniek: Een technisch sterke website presteert beter in de zoekresultaten. Het is daarom belangrijk om te kijken naar, onder andere, de beveiliging van de website (HTTPS), toegankelijkheid voor crawlers, snelheid van de website, en of de website geschikt is voor mobiele apparaten.
Een combinatie van al deze factoren bepaalt de ranking van een website in de zoekresultaten.
Na haar studie Marketing Management aan de Rijks Universiteit Groningen is Linda haar carrière begonnen als program manager bij een groot Frans bedrijf. Na enkele jaren heeft ze gekozen om verder te gaan met haar passie (online) marketing en versterkt ze het SEO team bij SDIM.